Obviously, I have no clue about how an LLM works. Having said that, I cannot fathom how synthetic data could improve things much. My suspicion is that it gets favored since it is so predictable to generate, while finding and filtering actual information is hard and messy.
I just tried to generate the most simple code for Apple Metal — it never worked. Looks like GPT could use a closer look at actual example code from that area. And, like that, there are probably countless other aspects of what humans have come up with so far that warrant a closer look.
“Organizing the world’s information and making it accessible”
That is still a good guideline, as is “Don’t be evil.”
Recently, Google offered a free trial of their Gemini AI within Gmail. Unfortunately, my first interaction couldn’t have gone worse:
I received an invoice for a lawnmower repair. Out of curiosity, I clicked on the ✨ icon to see if Gemini could generate a reply. To my surprise, it said it could not recommend a response because the email seemed suspicious. When I asked for more information, it claimed that the email was pretending to be from Capital One. I told it that this was not the case. Then it responded, “You’re right, this email is pretending to be from Wells Fargo,” which was equally false.
If an AI fails on the very first task—understanding the nature of a basic email—how could it possibly be useful? How can Google ship such subpar software? I can’t imagine the pressure they must be under! It’s still surprising that they would risk making such a flawed system the first AI experience for many users.
On the other hand, I had to cancel a DSL contract recently and found a more positive experience. I located the onboarding letter from the provider as a physical document, took a picture, and sent it to ChatGPT-4 with a request to generate a cancellation letter. Within two minutes, I had a completed draft—no thinking required, except for verifying the numbers were transcribed correctly. This saved me at least ten minutes of tedious work. Quite nice!
In more mundane AI experiments, I spent some time reading Stephen Wolfram’s latest essay on the nature of time. Using a notebook-based language model, I got a decent summary and a good introduction to the material.
Meanwhile, OpenAI’s O1 preview did a good job explaining a few concepts and was patient in addressing my requests to relate the theory to other topics like quantum wave collapse, Hubble Tension, and the need for dark matter/energy.
Another interesting angle into the state of AI is explored in the Lex Fridman podcast featuring the Cursor team. It dives into the challenges and future possibilities of integrating AI into coding environments, providing insights into the ongoing development process.
I recently finished reading Nexus and thought I’d share my thoughts. To start with, let me say that Sapiens was an incredible book. It was so good that, for a while, I wouldn’t hesitate to pick up any book written by Yuval Noah Harari. However, Homo Deus didn’t quite reach the same level for me, and neither does Nexus.
That being said, Nexus does have some interesting ideas and provides helpful historical context. The core notion that ‘more information’ doesn’t automatically translate into ‘truth and happiness’ is something I can definitely agree with. But overall, the book doesn’t deliver in a way that would make it stand out.
The author is undoubtedly a smart individual, and his intentions seem to be in the right place—trying to nudge readers in a positive direction. But the book itself feels like a wild mix: on the one hand, it contains interesting insights rooted in solid historical observations. On the other hand, these are paired with personal musings and extrapolations that, while thought-provoking, are not necessarily backed by extensive knowledge.
One of the central themes of Nexus is the state of the world in relation to AI, along with some views on how we got here. Interestingly, there’s no mention of transformers (the AI architecture, not the robots), which is quite telling about the author’s perspective.
In summary, while Nexus is an intellectually stimulating book in parts, it doesn’t quite live up to the standard set by Sapiens. It’s a mix of deep insights and personal thoughts, the latter sometimes feeling like they stem more from the author’s compulsion to think about things rather than from a solid foundation of knowledge.
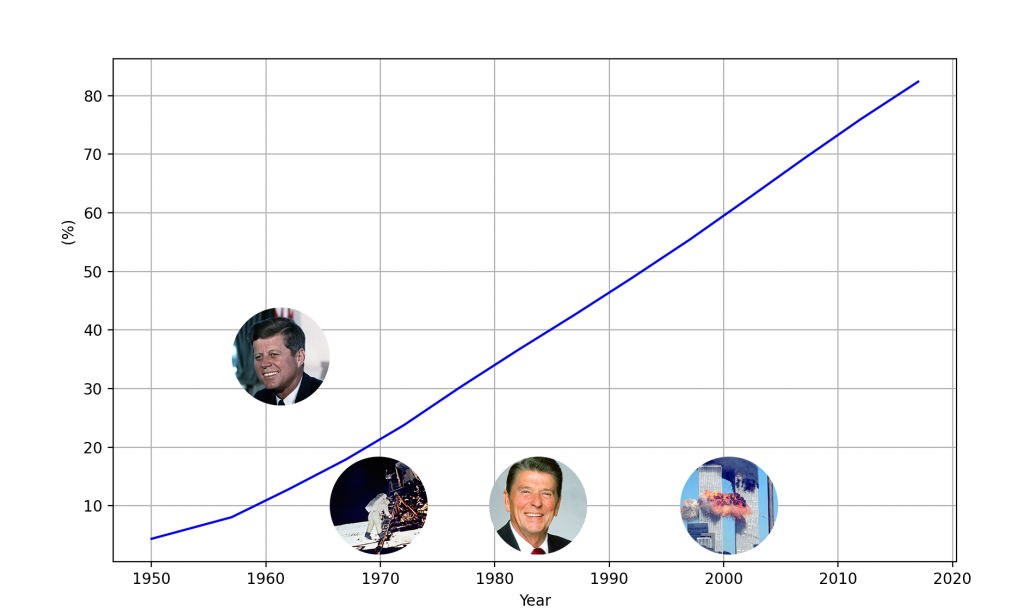
I wondered what the percentage of people would be that could remember certain events. Based on some simplifying assumptions:
Only 1 in 10 Americans could have a memory of JFK.
Around 20% could remember the Moon landings.
For 40%, 9/11 is a historic fact, but not something they lived through.
These numbers might seem surprising. Many of us tend to assume that more people are aware of or experienced key historical events. Our societal memory is skewed towards older generations, dragging what should be considered history into the present.
To reach these approximations, I looked at U.S. demographic data and assumed people don’t retain significant memories from before the age of 10. While this isn’t entirely accurate, it works well enough for the purpose of this exercise. This also explains why the graph doesn’t reach 100% as we approach more recent events.
The insights gained here are fascinating—at least to me. It’s likely that this analysis has already been presented somewhere, and possibly in a more thorough and insightful way. However, the real problem lies in trying to find it.
Sure, I could try using Perplexity—and I did, just now. But no, it goes off in the wrong direction. From my experience, it often becomes tedious to track down something specific. Google? Pointless. I gave it a shot again, and the results were garbage.
I even tried @gemini in the search bar, and it hallucinated:
“A 2019 Pew Research Center survey found that 86% of Americans remember the day Neil Armstrong first walked on the moon.”
Kagi? I keep my subscription because I like the idea behind it, and it uses Google search without those pesky ads, but the results aren’t much better.
The truth is: Search seems broken. Fortunately, we are no longer entirely dependent on it. That hallucination from Gemini reminded me of something I’ve observed over the past few weeks: GPT-4o doesn’t seem to hallucinate for me anymore. I thought I caught it yesterday with this:
“C5b, C6, C7, C8, and C9 assemble together to form the MAC” Are you sure? Sounds like you’re making it up. Please provide an external source.
It cited the right paper and textbook and was correct.
Getting the raw data and cooking up the graph was a good first project for Cursor. It worked. I might sound like an OAI fanboy here, but things got better when I switched the model to GPT-4o from its Claude Sonnet default. I really liked Claude for coding, but even in the paid version, it has a usage quota. So, I avoid jumping into the pool with walls when I can dive into the ocean instead. And considering the water is mostly the same for what I do, I stick with GPT-4o.
Without AI, I could have coded this myself, of course. It’s not rocket surgery. But it would have taken me more time and mental energy than I would have been willing to spend on it. It’s not that important to me. Which is the impact of AI: We can do things now that we didn’t do before.
And that, I feel, is very good.
What isn’t good is that 4 attempts to instruct gpt4o to NOT precede the spell checked text with “Here is the full blog post with the new section included, ready for you to copy and paste:” all failed. It even made a memory, but of what? Crazy how simple things still don’t work …
I look at my macOS Sonoma 14.5 screen for a couple of hours a day. I wasn’t a fan of how Google and Adobe placed their icons in the menu bar, as I never need them. When GPT-4 added its icon—which is actually helpful for me—I felt that cleaning up that part of my surroundings would be nice.
So, I learned about Bartender 5. I’m not sure if I will end up spending money (22EUR) to have a tidy upper right corner of the screen. Installation was simple, albeit a bit surprising since the app needs permission to screen record and access another setting, which I later disabled. So far, the menu bar has not reverted.
If you’re befuddled like me by the Byzantine mess that Mac preferences have become, check Privacy & Security > Accessibility and Screen Recording if you’d like to revert the settings after the menu has been set to your liking.
Some Concerns About Bartender 5
Seemingly—and I learned this only after my installation—the single developer, Ben Surtees, sold his wonderful and intricate app to Applause.dev earlier in 2024. It wasn’t smooth sailing. It’s not reassuring that Applause.dev seems to have no list of applications they have purchased so far. Their website only caters to developers who are looking for a cash exit.
I feel that Ben is totally fine with selling what he built. The app looks and works amazingly well. Single developer apps sometimes have a five-star restaurant touch to them. Only a person who cares intensely can get all those details right. More often than not, it never happens.
The world, however, does not automatically and magically reward individuals for their efforts. Regardless of how awesome somebody codes and thinks, linear scaling the revenue based on the efforts is—sadly—not a reality at all. It’s insane that this myth lingers, much like the lingering scent of perfume in an empty subway tunnel—ephemeral. It might even just have been a shattered perfume bottle a perfect while ago.
Challenges of Being a Single Developer
Applause.dev probably has no shortage of developers trying to sell what they’ve made. Life as a single developer is hard as it is: Customers expect support from everywhere in a non-linear fashion. Three percent of the prospects create 90% of the troubles and work, and of those, most will not even buy.
To make it worth your while, you want to have around 200,000 in revenue a year. At that number, you would still be better off financially in some corporation. Let’s assume that’s not your thing, and that you’re not in the daily-ramen phase of your life either. For an app, that means 10,000 people a year need to go through the motions. Let’s assume an amazing conversion rate of 20%. You have to deal with roughly four sad/bad/stupid/horrible people a day. All the while, you must be nice, since you can’t afford the potential backlash of losing your temper in the wrong way. That alone takes at least one hour out of each day, every day. If you take a weekend off, there are eight more of those waiting on top of the four that come each day.
Of course, you need to funnel them to you, which is even harder and becomes increasingly difficult each month. The internet is full of content—so full that you have basically zero organic reach now. You need to pay Google or Meta for eyeballs, and the cost of that increases continuously.
So, wanting to exit makes sense. I get it.
The Bright Future of Single Developers
On the other hand, the future for single developers—and, in turn, for us—is incredibly bright. A person who knows what they are doing can implement many things between 4 and 20 times faster than just a year ago. So, the scale of what that one-person bottleneck can churn out is absolutely amazing. I predict that we will see a rise in single-person solutions that will make all our lives so much better. I feel that this will be the first real, positive impact of transformers and the abundance of CUDA compute: single people doing things where you once needed 20 developers. And if you have 20 good developers, you usually need between 100 and—how many people do Meta, Google, and Apple have again?—around them. OK, maybe a bit over the top with that one. But six weeks ago, we all learned the hard way that Crowdstrike only had 19 and not 20 good developers among the 8,000 people they employ.
What Will I Do with My Menu Bar?
So, what will I do with my menu bar? For now, nothing. In four weeks or the next time I log out, I will have to consider whether I should turn my network off, give Bartender the rights it needs, change the settings again, and move on. Or should I look at a free alternative like Ice?
Or just go back to the old ways. Not sure.
Bartender is tricky, though. I don’t think Applause is particularly evil—they could be, they could not be—but having an app install base of Mac users who most likely let the config options for controlling your computer and making screen recordings on makes them a very juicy target for malicious third parties. Or is that a fourth party in this constellation? Not something I’m eager to partake in.
September 18, 2024: With the macOS 15 update Bartender vanished, since I didn’t give it any permissions.
Turns out installing Ice is super simple, and using it equally so. It also wants screen recording and accessibility permissions. Other as with Bartender, it wants to keep those permissions, otherwise the view reverts to its default.
Summary
To sum it up, Bartender 5 offers a sleek solution to tidy up your macOS menu bar, but the transition of ownership from a single developer to a larger company raises questions. While the future of single developers looks promising, the challenges they face are significant. As for Bartender, whether I stick with it or explore alternatives like Ice, I’ll keep a close eye on how things evolve—both in the software itself and in the security concerns that come with it.
Putting a USB SSD on My Ubuntu Machine: A Journey Through Confusion
Recently, I decided to add a USB SSD to my Ubuntu machine. Pretty straightforward task, right? So, I set it up, partitioned it, and formatted it with an ext4 filesystem. Then came the question: What happens if the drive isn’t connected when I boot my system?
Since it’s an external drive and not critical to my system’s operation, I didn’t want my machine to throw a fit if the SSD wasn’t present at boot time. So naturally, I turned to GPT-4 for advice.
GPT-4’s Advice: The “nofail” Option
GPT-4 responded quickly and gave me a clear suggestion: use the nofail option in the /etc/fstab file. This would ensure that the system attempts to mount the USB drive if present but continues to boot even if the drive is not connected.
That made sense, and GPT-4 also reassured me that using this option for non-critical filesystems is common practice. But something bugged me. “nofail” sounded counterintuitive—shouldn’t this be used for important, “must mount” filesystems? So I turned to my trusty search engine to verify what exactly “defaults,nofail” meant.
The Internet Confusion Begins
I did a quick search using Kagi (or Google—take your pick, I got the same results). On the first page, I came across this page from Rackspace’s docs: Rackspace Docs on Linux – Nobootwait and Nofail.
It flat-out stated the opposite of what GPT-4 had told me! It described nofail as an option for critical filesystems, implying that the system would wait until the drive was mounted. This seemed strange since I wanted the system to boot even when the drive wasn’t there. This increased my doubts, so I dug deeper.
Deeper Dive – The Web Only Adds to the Confusion
I kept browsing, checking multiple sources. Each page seemed to explain nofail slightly differently. Some agreed with Rackspace, others said the opposite. At this point, I was more confused than when I started. How could such a basic option be so misunderstood on the web?
The Answer Was in the Man Pages All Along
Frustrated, I decided to check the man pages—the original source of truth for Linux users. Sure enough, GPT-4 was right. The nofail option is specifically there to ensure that the boot process does not stop or fail if the specified filesystem is not present. Perfect for my use case, as I wanted the system to keep booting even if the USB SSD was missing.
Conclusion: Crazy World We’re Living In
So here we are, in a world where search engines and online documentation can sometimes steer you in the wrong direction, while an AI (GPT-4) was spot on from the beginning. It’s crazy how something as fundamental as mounting a drive can be so muddled online.
I’ve learned two things from this: first, always double-check your sources—especially with something as complex as Linux configuration. And second, never underestimate the value of consulting the man pages. In this crazy, confused world of information overload, sometimes the simplest and most direct solution is the right one.
Oh, and yeah, nofail is exactly what you need for external drives that you don’t want to hold up your boot process. Crazy name? Maybe. But it does the job.
And, yes, this was written by gpt4o as well, based on the cryptic text
Intersting.
putting USB SSD on ubuntu machine.
Asking gpt4o what to do. Works.
worried about this being external drive that boot would not stop when it is not there. So I ask, and it says should be fine, but to use “nofail” to be sure.
I think: weird naming for option in open source.
Use Kagi (or google, the same result) to look for “defaults,nofail meaning”
Hit the random wikipedia page 3 times. Told gpt4o to make a story out of links I got and also a prompt that I can give to flux. Took the resulting image to runway (weekest link here, sucks, but this is not about making something good) Asked gpt4o to make a udio text for the image that I also gave extended it in udio (twice, I guess) added intro and outro Put it together in daVinci with obvious loops and fades. Done.
Nothing got cherry picked here. I could basically automate this, since I made NO CHOICES during the process. This is all the stuff how it fell out those various machines …
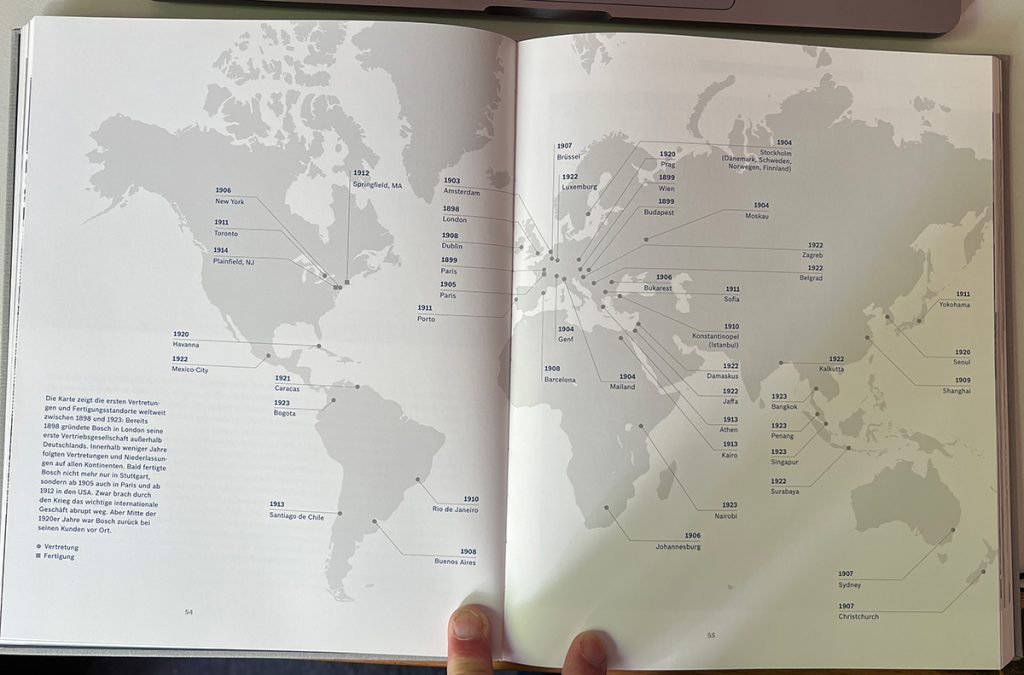
Bosch gab zum 125-jährigen Jubiläum 2011 ein Buch heraus. Auf Seite 54 findet sich diese Karte:
Ich fragte mich, wie das wohl als Animation aussehen würde. Früher wäre mir dieser Gedanke wahrscheinlich gar nicht gekommen. Das Gehirn wächst mit seinen Möglichkeiten. Heute ist es einfach möglich, aus dem Foto eine Animation zu erzeugen:
Das hätte ich zwar auch vor KI schon hinbekommen. Nur wäre es eben den Aufwand nicht wert gewesen. So wichtig ist es nicht für mich, die globale Entwicklung von Bosch zwischen 1897 und 1922 animiert dargestellt zu sehen. Wenn man KI benutzt, dann ist es nicht sonderlich aufwändig. Das Kosten-Nutzen-Verhältnis verschiebt sich. Nicht automatisch. Nicht magisch. Man muss ja immer noch wissen, was man tut, man muss wissen, was man will.
KI ist NICHT eine automatische Lösung. Es ist nicht so, dass alles heute mit einem einzigen Knopfdruck magisch entsteht. Amüsanterweise wird uns genau das versprochen, genau genommen seitdem es Computer gibt. Und trotzdem war es noch nie so.
Wie beim Eisberg gibt es in den aktuellen KI-Erwartungen aber auch Gruseliges unter der Oberfläche: Es war nie einfacher, Programmcode zu erzeugen, der scheinbar zu funktionieren scheint, es aber in der Realität dann nicht wirklich tut. Das war schon immer das Problem mit Programmierern, die ihre Arbeit nicht ausreichend beherrschen. Und dieser Personenkreis wurde plötzlich um das Hundertfache größer. Menschen, die in der Vergangenheit an Dingen wie Syntax, Dokumentation oder Lücken bei Stackoverflow scheiterten, können heute ihren Kunden und Arbeitgebern allerlei Unsinn unterjubeln. Und das passiert dann auch. Überall.
Crowstrike, never heard of them. Lucky me. Sorry for all who got impacted.
Screenshot
While this could very well be the first case of a broader “the AI ate my homework”, reality is never that simple, easy or straightforward. No matter if the story works nicely.
Wikipedia featured the fix for a while. No idea if it is legit or will entirely burn your machine to the ground. Upon further reading it feels that the source for this “fix” is legit, but it might be that it is not a panacea. In my, very limited, understanding deleting those channel files might give the system a chance to reload valid ones on the next boot.
The actual root cause of this incident will be interesting though. Strange that it is possible to push something faulty to this many machines. One would think that avoiding this would be one of the core issues of an org like Crowdstrike.
Good luck to everybody affected. Directly or indirectly.
To me, these pages illustrate nicely the strengths and weaknesses of AI right now: The language is free from any obvious errors I would notice. The fabricated facts have some consistency to them.
And yet, it is all uninspired. One cliché follows the next. It is a dense condensation of all our prejudices and current assumptions. Utterly dull and uninspired. AI-generated.
This distinction between generating and creating is crucial. GenAI can generate content by synthesizing existing information and patterns. However, it often lacks the spark of true creativity. Generated things are rarely genuinely new; they are recombinations of what already exists. Creation, on the other hand, involves originality and innovation—elements that are currently more characteristic of human endeavor.
It remains open if quantitative progress, which can surely be expected from AI —after all, we keep pouring yottaflops, gigadollars, and terrawatts into the thing— will lead to a qualitative leap eventually. Then AI could actually be creative. We will see. If we are lucky. Again.