I’m not a fan of TikTok. I think it has an almost evil genius in its ability to condition minds into something akin to human “Legehennen” (battery hens). In general, I have no issue with left-leaning publications. But let’s call out nonsense where we see it.
The Guardian article from December 12, 2024, claims that TikTok has a carbon footprint on par with Greece. That’s a serious claim. But if we break down the math, it starts to look suspicious.
The Math Behind the Claim
Let’s take the numbers they’re using and do some calculations:
Start with a total of 50 million metric tonnes of CO₂.
Divide by 1 billion users: that’s about 50 kg of CO₂ per user per year.
Assume a carbon intensity of 0.475 kg CO₂ per kWh. At that rate, 50 kg CO₂ corresponds to roughly 105 kWh/user/year.
Spread over a full year (8,760 hours), that’s about 12 W continuously per user.
But users only spend about 276 hours/year on TikTok. If we concentrate that 12 W into just the active usage time, you get 380 W per active user session.
So the math itself is internally consistent: given the initial assumptions, you end up with 380 W per active user.
Does 380 W per User Even Make Sense?
No. 380 W per user just for streaming short-form video is wildly implausible. It’s off by orders of magnitude. To put this in perspective, 380 W is like running several light bulbs just to serve you a single video feed. That’s massive.
In reality, data centers serving millions of users simultaneously do so at a much lower per-user energy cost. The number from these calculations strongly suggests that the initial carbon footprint figure or some fundamental assumption in that claim is questionable.
If TikTok truly had the same carbon footprint as an entire country with millions of citizens and heavy industry, it would be a global scandal. But we need to consider whether that initial data point (50 million metric tonnes of CO₂) makes sense, and what it includes. Is it capturing the entire business operation, including servers, distribution, all upstream supply chains, and user device energy?
Conclusion
It’s critical to apply common sense and do the math before swallowing claims like this. Even if you dislike TikTok, as I do, you have to recognize that equating its energy usage to that of Greece might be an exaggeration—or based on questionable data or assumptions.
At the end of the day, 380 W per user to serve video streams is “No Fucking Way” territory.
[[ O1 Pro took its time to write this, and during that creation I might even have used 380W ]]
I look at my macOS Sonoma 14.5 screen for a couple of hours a day. I wasn’t a fan of how Google and Adobe placed their icons in the menu bar, as I never need them. When GPT-4 added its icon—which is actually helpful for me—I felt that cleaning up that part of my surroundings would be nice.
So, I learned about Bartender 5. I’m not sure if I will end up spending money (22EUR) to have a tidy upper right corner of the screen. Installation was simple, albeit a bit surprising since the app needs permission to screen record and access another setting, which I later disabled. So far, the menu bar has not reverted.
If you’re befuddled like me by the Byzantine mess that Mac preferences have become, check Privacy & Security > Accessibility and Screen Recording if you’d like to revert the settings after the menu has been set to your liking.
Some Concerns About Bartender 5
Seemingly—and I learned this only after my installation—the single developer, Ben Surtees, sold his wonderful and intricate app to Applause.dev earlier in 2024. It wasn’t smooth sailing. It’s not reassuring that Applause.dev seems to have no list of applications they have purchased so far. Their website only caters to developers who are looking for a cash exit.
I feel that Ben is totally fine with selling what he built. The app looks and works amazingly well. Single developer apps sometimes have a five-star restaurant touch to them. Only a person who cares intensely can get all those details right. More often than not, it never happens.
The world, however, does not automatically and magically reward individuals for their efforts. Regardless of how awesome somebody codes and thinks, linear scaling the revenue based on the efforts is—sadly—not a reality at all. It’s insane that this myth lingers, much like the lingering scent of perfume in an empty subway tunnel—ephemeral. It might even just have been a shattered perfume bottle a perfect while ago.
Challenges of Being a Single Developer
Applause.dev probably has no shortage of developers trying to sell what they’ve made. Life as a single developer is hard as it is: Customers expect support from everywhere in a non-linear fashion. Three percent of the prospects create 90% of the troubles and work, and of those, most will not even buy.
To make it worth your while, you want to have around 200,000 in revenue a year. At that number, you would still be better off financially in some corporation. Let’s assume that’s not your thing, and that you’re not in the daily-ramen phase of your life either. For an app, that means 10,000 people a year need to go through the motions. Let’s assume an amazing conversion rate of 20%. You have to deal with roughly four sad/bad/stupid/horrible people a day. All the while, you must be nice, since you can’t afford the potential backlash of losing your temper in the wrong way. That alone takes at least one hour out of each day, every day. If you take a weekend off, there are eight more of those waiting on top of the four that come each day.
Of course, you need to funnel them to you, which is even harder and becomes increasingly difficult each month. The internet is full of content—so full that you have basically zero organic reach now. You need to pay Google or Meta for eyeballs, and the cost of that increases continuously.
So, wanting to exit makes sense. I get it.
The Bright Future of Single Developers
On the other hand, the future for single developers—and, in turn, for us—is incredibly bright. A person who knows what they are doing can implement many things between 4 and 20 times faster than just a year ago. So, the scale of what that one-person bottleneck can churn out is absolutely amazing. I predict that we will see a rise in single-person solutions that will make all our lives so much better. I feel that this will be the first real, positive impact of transformers and the abundance of CUDA compute: single people doing things where you once needed 20 developers. And if you have 20 good developers, you usually need between 100 and—how many people do Meta, Google, and Apple have again?—around them. OK, maybe a bit over the top with that one. But six weeks ago, we all learned the hard way that Crowdstrike only had 19 and not 20 good developers among the 8,000 people they employ.
What Will I Do with My Menu Bar?
So, what will I do with my menu bar? For now, nothing. In four weeks or the next time I log out, I will have to consider whether I should turn my network off, give Bartender the rights it needs, change the settings again, and move on. Or should I look at a free alternative like Ice?
Or just go back to the old ways. Not sure.
Bartender is tricky, though. I don’t think Applause is particularly evil—they could be, they could not be—but having an app install base of Mac users who most likely let the config options for controlling your computer and making screen recordings on makes them a very juicy target for malicious third parties. Or is that a fourth party in this constellation? Not something I’m eager to partake in.
September 18, 2024: With the macOS 15 update Bartender vanished, since I didn’t give it any permissions.
Turns out installing Ice is super simple, and using it equally so. It also wants screen recording and accessibility permissions. Other as with Bartender, it wants to keep those permissions, otherwise the view reverts to its default.
Summary
To sum it up, Bartender 5 offers a sleek solution to tidy up your macOS menu bar, but the transition of ownership from a single developer to a larger company raises questions. While the future of single developers looks promising, the challenges they face are significant. As for Bartender, whether I stick with it or explore alternatives like Ice, I’ll keep a close eye on how things evolve—both in the software itself and in the security concerns that come with it.
Putting a USB SSD on My Ubuntu Machine: A Journey Through Confusion
Recently, I decided to add a USB SSD to my Ubuntu machine. Pretty straightforward task, right? So, I set it up, partitioned it, and formatted it with an ext4 filesystem. Then came the question: What happens if the drive isn’t connected when I boot my system?
Since it’s an external drive and not critical to my system’s operation, I didn’t want my machine to throw a fit if the SSD wasn’t present at boot time. So naturally, I turned to GPT-4 for advice.
GPT-4’s Advice: The “nofail” Option
GPT-4 responded quickly and gave me a clear suggestion: use the nofail option in the /etc/fstab file. This would ensure that the system attempts to mount the USB drive if present but continues to boot even if the drive is not connected.
That made sense, and GPT-4 also reassured me that using this option for non-critical filesystems is common practice. But something bugged me. “nofail” sounded counterintuitive—shouldn’t this be used for important, “must mount” filesystems? So I turned to my trusty search engine to verify what exactly “defaults,nofail” meant.
The Internet Confusion Begins
I did a quick search using Kagi (or Google—take your pick, I got the same results). On the first page, I came across this page from Rackspace’s docs: Rackspace Docs on Linux – Nobootwait and Nofail.
It flat-out stated the opposite of what GPT-4 had told me! It described nofail as an option for critical filesystems, implying that the system would wait until the drive was mounted. This seemed strange since I wanted the system to boot even when the drive wasn’t there. This increased my doubts, so I dug deeper.
Deeper Dive – The Web Only Adds to the Confusion
I kept browsing, checking multiple sources. Each page seemed to explain nofail slightly differently. Some agreed with Rackspace, others said the opposite. At this point, I was more confused than when I started. How could such a basic option be so misunderstood on the web?
The Answer Was in the Man Pages All Along
Frustrated, I decided to check the man pages—the original source of truth for Linux users. Sure enough, GPT-4 was right. The nofail option is specifically there to ensure that the boot process does not stop or fail if the specified filesystem is not present. Perfect for my use case, as I wanted the system to keep booting even if the USB SSD was missing.
Conclusion: Crazy World We’re Living In
So here we are, in a world where search engines and online documentation can sometimes steer you in the wrong direction, while an AI (GPT-4) was spot on from the beginning. It’s crazy how something as fundamental as mounting a drive can be so muddled online.
I’ve learned two things from this: first, always double-check your sources—especially with something as complex as Linux configuration. And second, never underestimate the value of consulting the man pages. In this crazy, confused world of information overload, sometimes the simplest and most direct solution is the right one.
Oh, and yeah, nofail is exactly what you need for external drives that you don’t want to hold up your boot process. Crazy name? Maybe. But it does the job.
And, yes, this was written by gpt4o as well, based on the cryptic text
Intersting.
putting USB SSD on ubuntu machine.
Asking gpt4o what to do. Works.
worried about this being external drive that boot would not stop when it is not there. So I ask, and it says should be fine, but to use “nofail” to be sure.
I think: weird naming for option in open source.
Use Kagi (or google, the same result) to look for “defaults,nofail meaning”
Crowstrike, never heard of them. Lucky me. Sorry for all who got impacted.
Screenshot
While this could very well be the first case of a broader “the AI ate my homework”, reality is never that simple, easy or straightforward. No matter if the story works nicely.
Wikipedia featured the fix for a while. No idea if it is legit or will entirely burn your machine to the ground. Upon further reading it feels that the source for this “fix” is legit, but it might be that it is not a panacea. In my, very limited, understanding deleting those channel files might give the system a chance to reload valid ones on the next boot.
The actual root cause of this incident will be interesting though. Strange that it is possible to push something faulty to this many machines. One would think that avoiding this would be one of the core issues of an org like Crowdstrike.
Good luck to everybody affected. Directly or indirectly.
What does Meta do? It turns people into money. Those that are on the Internet, that is—not in a Soylent Green kind of way.
At least, that was the mantra up until 2018. Then Cambridge Analytica broke. And the Q2 2018 earnings gave an inkling of the possibility that not a fixed—and also rather large—ratio of people entering the Internet would become, just like magic, Facebook users.
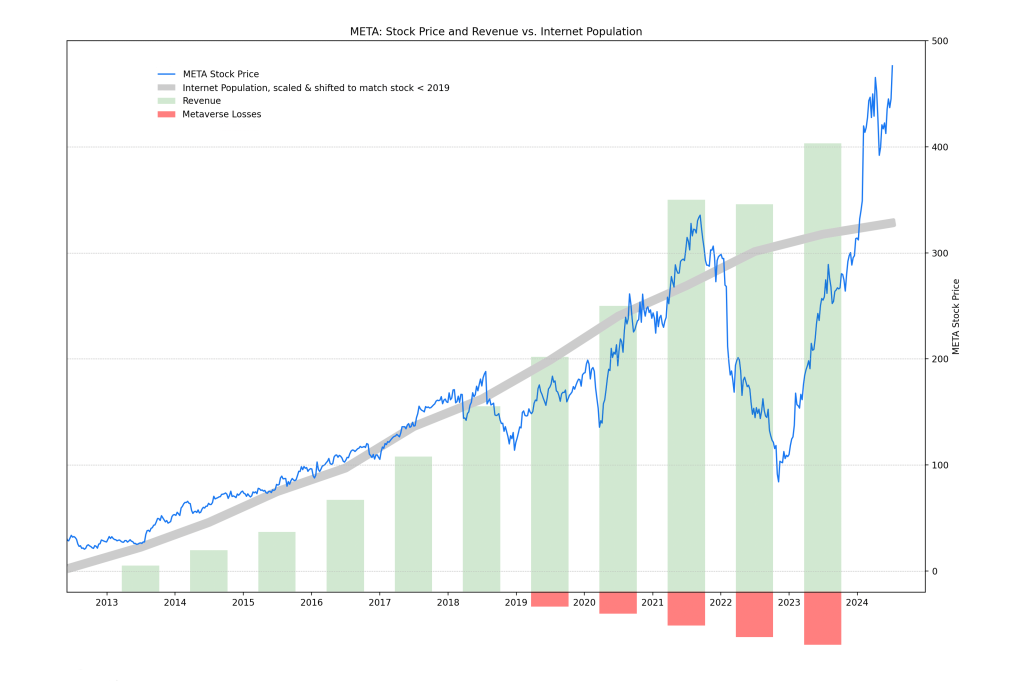
Later, people seemed to forget about the fact that they get algorithmically nudged in Zuck’s wonderland every step of the way. Wall Street itself realized that revenues at 1 Hacker Way actually kept on rising—until they jumped in 2021. COVID, remember?
The Metaverse, however, wasn’t really that great of a hit, and after the virus bonus revenue fell back in line the following year, FB lost a staggering two-thirds of its value. A trillion-dollar meme stock.
An attribute that it then turned into current heights via hitching itself to the AI bandwagon.
Releasing the LLaMA weights is undoubtedly a commendable move. It sounds utterly impressive when you can claim, “While we’re working on today’s products and models, we’re also working on the research we need to advance for LLaMA 5, 6, and 7 in the coming years and beyond to develop full general intelligence,” in an earnings call. Pretty much like that strange man proclaimed five years ago: “I want 5G, and even 6G, technology in the United States as soon as possible.” Numbers: They go up, up, and up.
Hype aside, I am not really aware of any practical applications for LLaMA 3. Zuck bought lots of GPUs. Both Jensen and I are happy about that. Maybe they thought they had all this data that people have entered in their apps. Maybe they could train a LLM on it. With GPT-3, there was this notion that the size of the training corpus was all that mattered. After all, OpenAI’s chatbot was such a wonder, and it jumped into existence just via the increase of its training data. I speculate that a trillion training tokens derived from FB discussions yield surprisingly little meaningful reasoning power. Especially compared to actual content like, for instance, Wikipedia.
The pressure to come up with something must have weighed heavily on 1 Hacker Way. As those two transformer-based applications (LLMs and Image Diffusers) broke into public view and kicked the world into a frenzy that seemingly became the new normal, Meta itself had just spent around $50 billion on developing, well, the Metaverse. Which received rather little positive reaction, to put it mildly.
The total and utter failure of Zuck’s idea to come up with a whole new thing left Meta with no choice but to jump on the AI hype PR scheme. And up to this day, it has worked rather well. While revenue is ticking along as expected, the stock is kissing new heights. For now.
So, what’s next? Nobody knows.
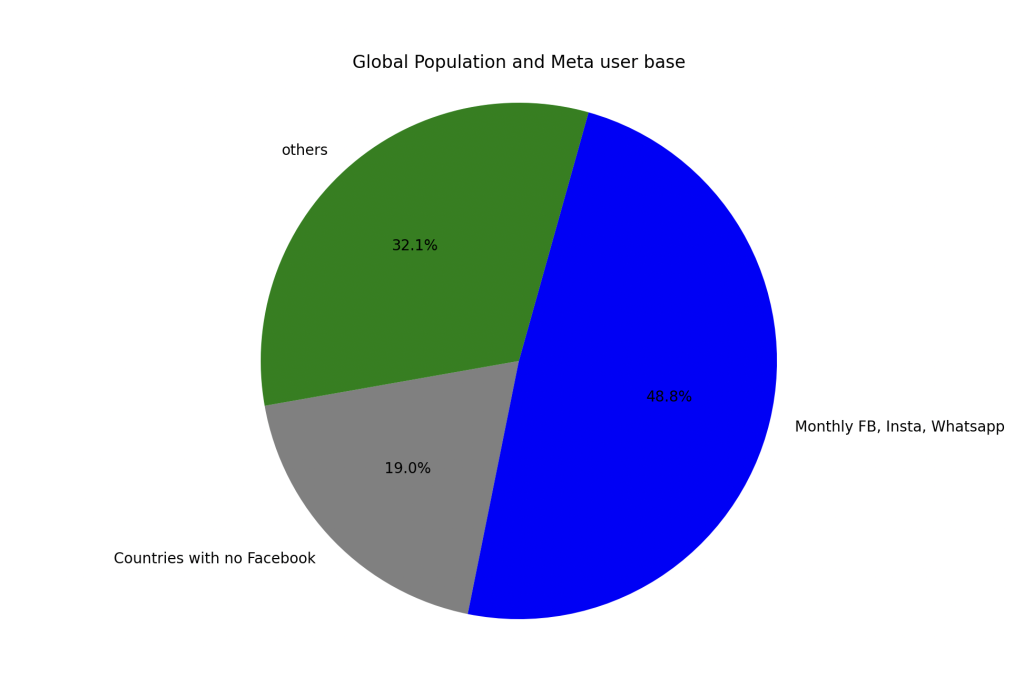
What will happen is that Internet population growth will end. There are simply no more people left that could join. Pretty much everybody who could go online already has done so. While 25% of the world’s population are younger than 15, many of them live in underdeveloped parts of Africa. Furthermore, young people hardly flock eagerly into the Meta family of products once they get their first Internet device.
Meta’s revenue growth would therefore stall together with the plateau in its user count. While they continue to make a lot of money, a PE ratio of currently around 30 is expecting something else: More money. You need to grow profits to justify such a valuation. A quick way to bump revenues would be to reduce costs. Twitter is still up and running, despite Mr. Musk letting go of most of its workforce. A tempting move that could save the numbers for a quarter or two at Menlo Park as well. The problem is that this approach works only briefly: Costs go down to zero. But not more.
Which means that Meta needs to increase revenues while user numbers can no longer grow.
Can Zuck’s companies accomplish that? They might, but it would not be pretty: Billions of people have delegated a great part of their social existence into the “Meta Family of Products”. (What’s in a name?) A sticky situation in itself. Add to that the addictive aspects that rival nicotine, and you realize that half the planet as a user base won’t go anywhere fast.
Wealth as well as the inflexibility to change app use or social topology both tend to grow with increasing age. Meta owns people’s time and attention in staggering amounts.
Here comes the part that isn’t pretty: it is rather easy to manipulate people online. Tech is able to do it. And will increasingly be. There is a threshold after which you no longer realize that you got nudged.
When the magician manages to direct your attention successfully, all sorts of things are possible. With a serious difference: Magic lives from the effect, that the outcome shows you, that you must have missed something. You are supposed to notice that it is impossible what just happened.
Manipulation to gain, aka advertisement, has a different aim: You should be made to act in certain ways, all the while thinking that you want to do that.
The total spending of Meta family users is responsible for a mind-boggling share of GDP. And, as discussed, most of the users will not go anywhere. If Meta does not f*ck up royally, pretty much half of the global adults will continue to point their noses, eyes, minds, and wallets its way.
Turning on the manipulation engine will not be one deliberate conscious act or one magnificent large piece of software. Lots of little changes will yield lots of little benefits. With billions of people, you can do a whole lot of A/B testing. Nobody will notice. Everybody’s feed is different and the fact that you see wording that is ever so slightly different will not trigger any of the societal mechanisms that will raise a reaction.
Jacob Riis used flash photography at the end of the 19th century to show the world how poor people lived in NYC, and he changed the world for the better. I cannot imagine how we can illuminate the modern plight of getting nudged into an ultimately unhappy existence that looms on the horizon.
LLMs have their limits, and where they excel makes a difference. As of June 2024, they continue to evolve. Anthrop\c Claude 3.5 works well for coding simple things with Python. It feels like the LLM has been heavily trained on existing code. Actually, it might be just as good in other applications as well. I wouldn’t know since I only use it for coding right now. Even on the paid plan, it has a message limit, which feels very 2023. So, I use the limited interaction where I get the highest benefit, which is coding. The artifact window is a great idea, and the speed of generation is appreciated. With gpt4o, I had to interleave work: make a request, switch to a different task while gpt4o sputtered out characters at Morse code speed. It probably runs on a colony of squids at the bottom of the Mariana Trench that OpenAI taught how to use Morse code with each arm.
And yes, an image like this I create with gpt4o. I don’t even know if Claude can do that. I don’t mind having multiple LLMs. I am gladly paying for both of them, as I do for search. Right now, I am very happy that there is more than one solution. I tried to use Google AI, but it was too complicated to figure out. To find the offering that fit mit my needs. And I am not aware of a key feature that I could only do with them. They already have all my email, read the entire Internet. If I can avoid it, I would not like to help them any further. Sure, if they were as good at coding as Claude, I would use them in a second. I have morals, but I cannot save the world single-handedly either.
One of the bigger fears I have is that LLMs might take the same turn that Google Search did. It was a great idea. It worked great, allowing for a phase of the Internet in the early 2000s that was very promising. Then it became what we suffer from today—a swamp. Barely functional. Generating around $150 profit for Google per user annually. Which means companies make more. Which means that I loose even more than that. The costs of using Google Search by being manipulated are much higher now than its benefits. The SEO world that Google Search presents is not a nice one. I happily give Kagi money to have some distance from that swamp.
I didn’t find that mythical UrBlog of mine that I mentioned in the first post of the recently recovered one. The loss of something digital is weird. Since it lacks the inevitability of entropy that all other things have, it is especially infuriating. It could have been prevented.
Oh well.
During the search, I came across some other things from the past. I had written a ‘meme tracker’ in the early 2000s called BlogsNow. It would reliably detect which links gained popularity. Back then, the so-called “Blogosphere” was a crazy mix of all sorts of things.
Finding the data for it got me thinking about the status of those 7 million weblogs. How many would still be updated after two decades? I had just seen myself that it is not easy.
There are around 3500 site left that still get updated regularly. I didn’t spend too much time on the parser. There is a margin of error. But one in two thousand is a pretty strong filter.
When clicking around, I was surprised that some of the pages are rather interesting and surprising. So I added a random blog link on my main page.
There are layers to what happens now with stocks and stories around it. I think it will end in tears. Trading options on the phone is a reality. And weird. Other, by now established, retail traders like TD or Schwab have you go through some lengthy process before you can dabble in options. It feels like Robinhood let you do it without much fuzz. Fun game. As long as it lasts. RH is said to have $20B AUM. Almost as big as Citadel with its $35B AUM. Citadel is also a “Market Maker”. An entity that connects buyers and sellers of stocks. Something Bernie Madoff did before he went off the deep end. Bernie also invented “Payment for oder flow“. A scheme were the market maker pays for a third party to bring clients in. Robinhood makes most of its money from these kind of deals. It routes many of the trades that its 12 million customers make via Citadel. Bernie is busy right now, he can not do it, even if it he wanted to.
The plot thickens when we look at Citadell backing Melvin with $2.75B earlier this week. Melvin had shorted, among other actors, ailing games retailer chain GME. A short is a promise to provide a given stock at a given date for a given price. A great contract if you can get the stock cheaper than that. A really shitty contract if you can not. While the money you can make is limited by the price will be. The money you can loose has no such limit. If I would have shorted Tesla when I though their pricing was just outrageous, I would have lost 4 dollars for each dollar that I would have made that bet (short trade) with. I did not. Melvin did short GME though. And the price for GMA has gone up. Like allot.
What happened next? Robinhood, that company that makes most of its money with Citadel, stopped allowing people to buy GME stock on their platform. Basically manipulating the market. Preventing that the people that congregate on CondeNasts reddit in the WallStreetBets section from keeping the price up, or raising it even further.
It is pretty naive that people raise their pitch forks when in fact they only hold life sized paper cut outs of said farming devices in their angrily shaking fists. They seem to ignore the fact, that it is the people on the other side of the moat that gave them to them as a trade for the real thing and some confetti animation.
So, yes, it will end in tears. The wsb / GME story. As well as Robinhood, as well as the concept that all that money from your bail out check and that you saved by not going to Bali and that you put ‘into the market’ will get you instant riches.
In the end of every bubble the audience needs to get broadened. One needs more people to join the party. To keep the thing going for just one more round. In that it is not unlike the phase of a loosing war: All sorts of people get recruited to ‘turn things around’. The DJIA touched 31K. Where do you think would it go from here? The concept of asset price inflation can only carry you so far.
But I have been betting on a falling market since it was overpriced at 11,500. The first time. More than 20 years ago.
Sunday morning, and Breakfast will only be served in 15 minutes.
Not feeling to open a book I visit:
http://en.wikipedia.org/wiki/Special:Random
A song comes up. Turns out I don’t have it, but I like it.
The iTunes music gave me grief before. So I use Amazon.
Or, let’s say I try to.
A song with a wikipedia page is obviously easy to find.
I can preview it. Yes, it is what I thought it would be.
No surprise that the purchase button is easy to.
They have a new player / app they like to push.
The old amazon downloader did not cause any troubles,
so I choose that one.
The file downloads in no time. That USED to be the problem:
Getting those large files to your computer.
Clicking on it, the mac tells me that this app is from an unidentified
developer.
In system preferences I tell it to open it anyway.
It does, but shows an empty screen.
In my downloads is still the amazon file. I click on that one.
Nothing happens. Well, not really nothing: The downloaded file
vanished.
Then I go in Amazon to my purchases music. The song is not there
either. The 0.89 USD I spent will probably the only memory of those
3:18 (the length of the song) that I spent to get this song.
Buying music should be easy in 2014. It turns out in my specific
way of trying this it totally is not. I don’t buy music often. So I don’t feel
like researching all that might be involved.
I rather ramble here about it. Also since it is quiet symptomatic:
The actual act of copying a couple of bits to my computer is such a
small part of the overal action. It used to be that DRM was part of
the problem. It no longer is. Still have I have to deal with interfaces
and software that changes / breaks every time I like to use it.
The background is that the people running and maintaining these
systems do not care for the “Alpha to Omega – Experience†enough.
The late Mr Jobs was really good at making sure that things ran
as smooth as possible for certain flows from start to finish. If you don’t
then with computers and systems lots of ‘stuff’ will creep into the flow.
And the system will start depending on this extra stuff of other parts of
the system.
If you think that Byzantine bureaucracy was horrible then you have
no idea how our digital future will be.