Since more than 40 years there are HP printers that are connected to Apple computers. It is a simple thing: Some document is in the computer, it should get printed on paper. Happened in this specific Apple/HP combination many billions of times. HP’s market cap is around 35,470,000,000 dollars right now. That of Apple is 3,400,000,000,000.
Two devices connecting for this super simple thing. Should be easy in 2024.
IT IS NOT.
Fucking not.
The latest macOS Sonoma 15.1 will not work reliably with the HP Color LaserJet Pro 4202dn.
Printing a document multiple times will only work when you open the print dialog as many times and print one page.
The printer insists that it wants to double-sided print.
I spent hours with this. Tried everything. It did not work out of the box. Neither does it now.
Again: All I want is to print a simple text document.
Enshitification.
Here it is not intended. But infuriating. I love my MacBook Pro. The design for the HP printer I personally like. The hardware of it seems to be built right. But the software that moves the data to the printer does not work with the software of the printer. A task that should be solved since more than 40 years.
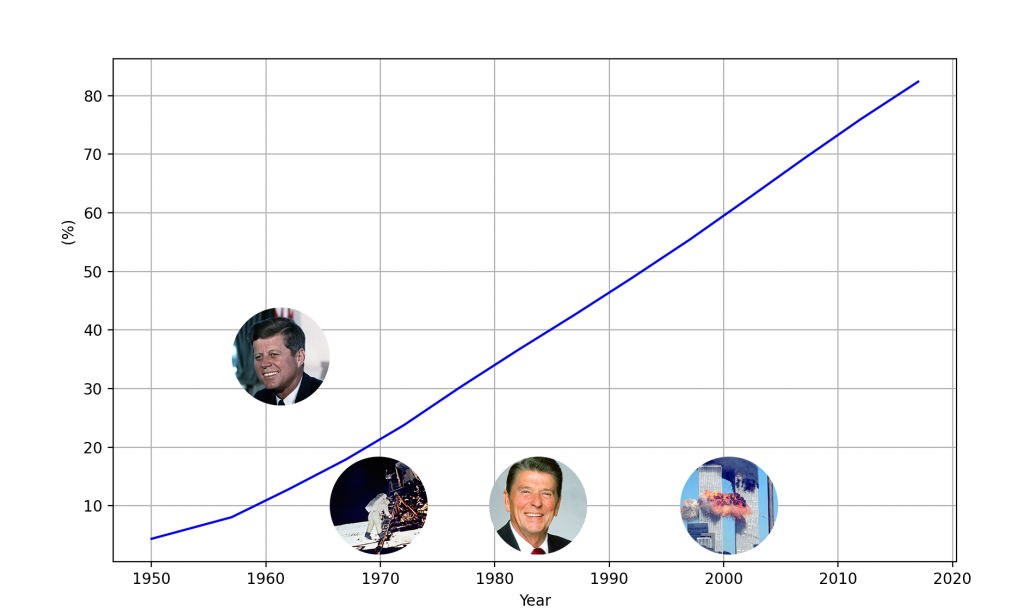
I wondered what the percentage of people would be that could remember certain events. Based on some simplifying assumptions:
Only 1 in 10 Americans could have a memory of JFK.
Around 20% could remember the Moon landings.
For 40%, 9/11 is a historic fact, but not something they lived through.
These numbers might seem surprising. Many of us tend to assume that more people are aware of or experienced key historical events. Our societal memory is skewed towards older generations, dragging what should be considered history into the present.
To reach these approximations, I looked at U.S. demographic data and assumed people don’t retain significant memories from before the age of 10. While this isn’t entirely accurate, it works well enough for the purpose of this exercise. This also explains why the graph doesn’t reach 100% as we approach more recent events.
The insights gained here are fascinating—at least to me. It’s likely that this analysis has already been presented somewhere, and possibly in a more thorough and insightful way. However, the real problem lies in trying to find it.
Sure, I could try using Perplexity—and I did, just now. But no, it goes off in the wrong direction. From my experience, it often becomes tedious to track down something specific. Google? Pointless. I gave it a shot again, and the results were garbage.
I even tried @gemini in the search bar, and it hallucinated:
“A 2019 Pew Research Center survey found that 86% of Americans remember the day Neil Armstrong first walked on the moon.”
Kagi? I keep my subscription because I like the idea behind it, and it uses Google search without those pesky ads, but the results aren’t much better.
The truth is: Search seems broken. Fortunately, we are no longer entirely dependent on it. That hallucination from Gemini reminded me of something I’ve observed over the past few weeks: GPT-4o doesn’t seem to hallucinate for me anymore. I thought I caught it yesterday with this:
“C5b, C6, C7, C8, and C9 assemble together to form the MAC” Are you sure? Sounds like you’re making it up. Please provide an external source.
It cited the right paper and textbook and was correct.
Getting the raw data and cooking up the graph was a good first project for Cursor. It worked. I might sound like an OAI fanboy here, but things got better when I switched the model to GPT-4o from its Claude Sonnet default. I really liked Claude for coding, but even in the paid version, it has a usage quota. So, I avoid jumping into the pool with walls when I can dive into the ocean instead. And considering the water is mostly the same for what I do, I stick with GPT-4o.
Without AI, I could have coded this myself, of course. It’s not rocket surgery. But it would have taken me more time and mental energy than I would have been willing to spend on it. It’s not that important to me. Which is the impact of AI: We can do things now that we didn’t do before.
And that, I feel, is very good.
What isn’t good is that 4 attempts to instruct gpt4o to NOT precede the spell checked text with “Here is the full blog post with the new section included, ready for you to copy and paste:” all failed. It even made a memory, but of what? Crazy how simple things still don’t work …
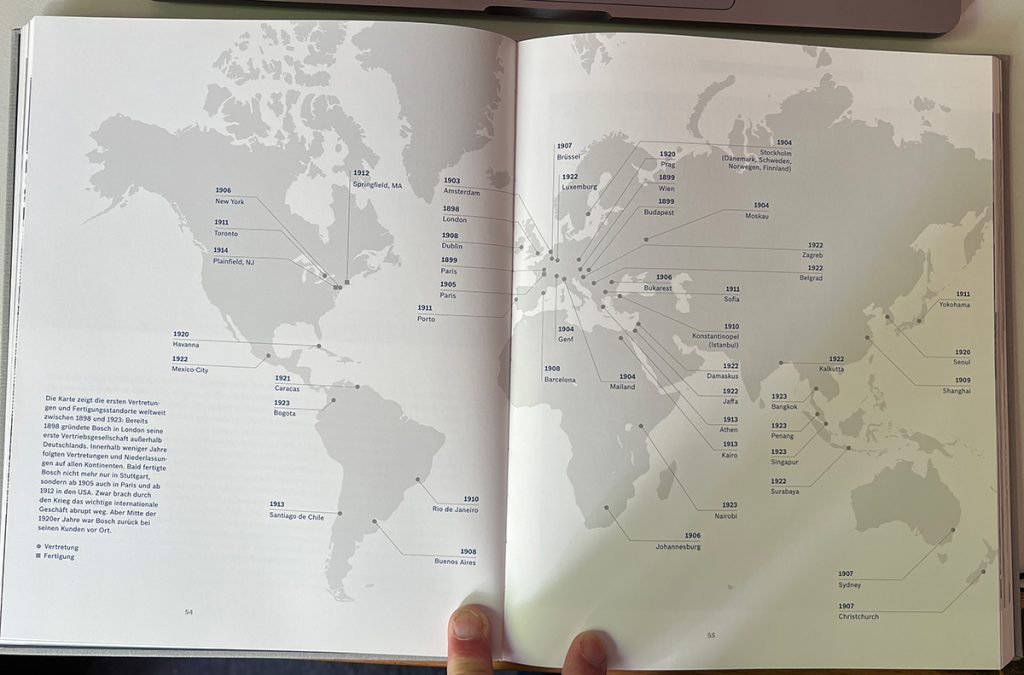
Bosch gab zum 125-jährigen Jubiläum 2011 ein Buch heraus. Auf Seite 54 findet sich diese Karte:
Ich fragte mich, wie das wohl als Animation aussehen würde. Früher wäre mir dieser Gedanke wahrscheinlich gar nicht gekommen. Das Gehirn wächst mit seinen Möglichkeiten. Heute ist es einfach möglich, aus dem Foto eine Animation zu erzeugen:
Das hätte ich zwar auch vor KI schon hinbekommen. Nur wäre es eben den Aufwand nicht wert gewesen. So wichtig ist es nicht für mich, die globale Entwicklung von Bosch zwischen 1897 und 1922 animiert dargestellt zu sehen. Wenn man KI benutzt, dann ist es nicht sonderlich aufwändig. Das Kosten-Nutzen-Verhältnis verschiebt sich. Nicht automatisch. Nicht magisch. Man muss ja immer noch wissen, was man tut, man muss wissen, was man will.
KI ist NICHT eine automatische Lösung. Es ist nicht so, dass alles heute mit einem einzigen Knopfdruck magisch entsteht. Amüsanterweise wird uns genau das versprochen, genau genommen seitdem es Computer gibt. Und trotzdem war es noch nie so.
Wie beim Eisberg gibt es in den aktuellen KI-Erwartungen aber auch Gruseliges unter der Oberfläche: Es war nie einfacher, Programmcode zu erzeugen, der scheinbar zu funktionieren scheint, es aber in der Realität dann nicht wirklich tut. Das war schon immer das Problem mit Programmierern, die ihre Arbeit nicht ausreichend beherrschen. Und dieser Personenkreis wurde plötzlich um das Hundertfache größer. Menschen, die in der Vergangenheit an Dingen wie Syntax, Dokumentation oder Lücken bei Stackoverflow scheiterten, können heute ihren Kunden und Arbeitgebern allerlei Unsinn unterjubeln. Und das passiert dann auch. Überall.
What does Meta do? It turns people into money. Those that are on the Internet, that is—not in a Soylent Green kind of way.
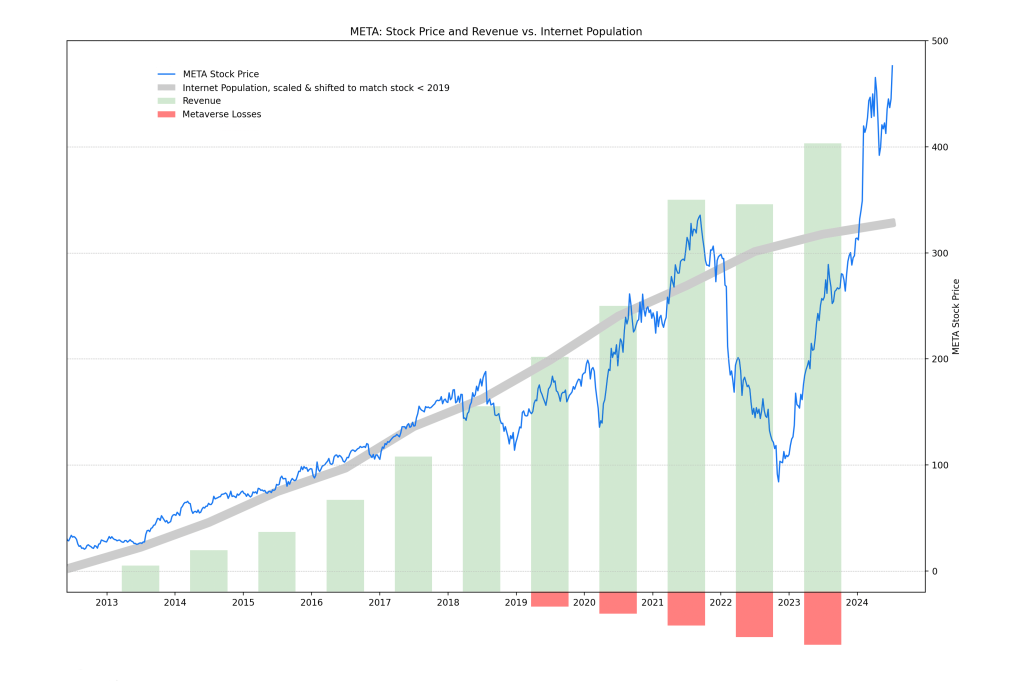
At least, that was the mantra up until 2018. Then Cambridge Analytica broke. And the Q2 2018 earnings gave an inkling of the possibility that not a fixed—and also rather large—ratio of people entering the Internet would become, just like magic, Facebook users.
Later, people seemed to forget about the fact that they get algorithmically nudged in Zuck’s wonderland every step of the way. Wall Street itself realized that revenues at 1 Hacker Way actually kept on rising—until they jumped in 2021. COVID, remember?
The Metaverse, however, wasn’t really that great of a hit, and after the virus bonus revenue fell back in line the following year, FB lost a staggering two-thirds of its value. A trillion-dollar meme stock.
An attribute that it then turned into current heights via hitching itself to the AI bandwagon.
Releasing the LLaMA weights is undoubtedly a commendable move. It sounds utterly impressive when you can claim, “While we’re working on today’s products and models, we’re also working on the research we need to advance for LLaMA 5, 6, and 7 in the coming years and beyond to develop full general intelligence,” in an earnings call. Pretty much like that strange man proclaimed five years ago: “I want 5G, and even 6G, technology in the United States as soon as possible.” Numbers: They go up, up, and up.
Hype aside, I am not really aware of any practical applications for LLaMA 3. Zuck bought lots of GPUs. Both Jensen and I are happy about that. Maybe they thought they had all this data that people have entered in their apps. Maybe they could train a LLM on it. With GPT-3, there was this notion that the size of the training corpus was all that mattered. After all, OpenAI’s chatbot was such a wonder, and it jumped into existence just via the increase of its training data. I speculate that a trillion training tokens derived from FB discussions yield surprisingly little meaningful reasoning power. Especially compared to actual content like, for instance, Wikipedia.
The pressure to come up with something must have weighed heavily on 1 Hacker Way. As those two transformer-based applications (LLMs and Image Diffusers) broke into public view and kicked the world into a frenzy that seemingly became the new normal, Meta itself had just spent around $50 billion on developing, well, the Metaverse. Which received rather little positive reaction, to put it mildly.
The total and utter failure of Zuck’s idea to come up with a whole new thing left Meta with no choice but to jump on the AI hype PR scheme. And up to this day, it has worked rather well. While revenue is ticking along as expected, the stock is kissing new heights. For now.
So, what’s next? Nobody knows.
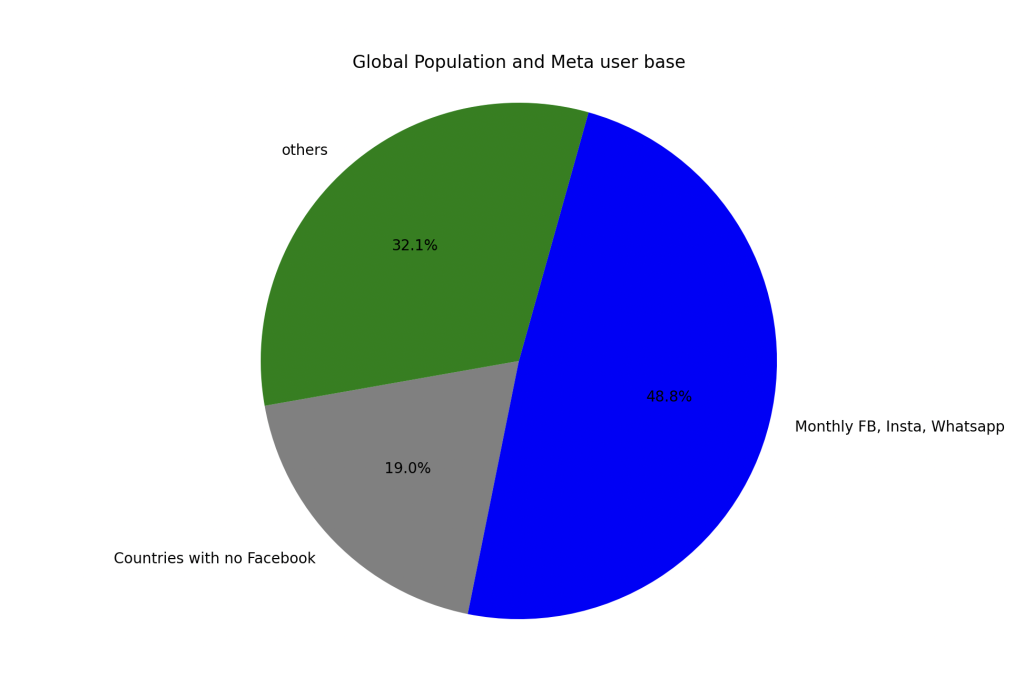
What will happen is that Internet population growth will end. There are simply no more people left that could join. Pretty much everybody who could go online already has done so. While 25% of the world’s population are younger than 15, many of them live in underdeveloped parts of Africa. Furthermore, young people hardly flock eagerly into the Meta family of products once they get their first Internet device.
Meta’s revenue growth would therefore stall together with the plateau in its user count. While they continue to make a lot of money, a PE ratio of currently around 30 is expecting something else: More money. You need to grow profits to justify such a valuation. A quick way to bump revenues would be to reduce costs. Twitter is still up and running, despite Mr. Musk letting go of most of its workforce. A tempting move that could save the numbers for a quarter or two at Menlo Park as well. The problem is that this approach works only briefly: Costs go down to zero. But not more.
Which means that Meta needs to increase revenues while user numbers can no longer grow.
Can Zuck’s companies accomplish that? They might, but it would not be pretty: Billions of people have delegated a great part of their social existence into the “Meta Family of Products”. (What’s in a name?) A sticky situation in itself. Add to that the addictive aspects that rival nicotine, and you realize that half the planet as a user base won’t go anywhere fast.
Wealth as well as the inflexibility to change app use or social topology both tend to grow with increasing age. Meta owns people’s time and attention in staggering amounts.
Here comes the part that isn’t pretty: it is rather easy to manipulate people online. Tech is able to do it. And will increasingly be. There is a threshold after which you no longer realize that you got nudged.
When the magician manages to direct your attention successfully, all sorts of things are possible. With a serious difference: Magic lives from the effect, that the outcome shows you, that you must have missed something. You are supposed to notice that it is impossible what just happened.
Manipulation to gain, aka advertisement, has a different aim: You should be made to act in certain ways, all the while thinking that you want to do that.
The total spending of Meta family users is responsible for a mind-boggling share of GDP. And, as discussed, most of the users will not go anywhere. If Meta does not f*ck up royally, pretty much half of the global adults will continue to point their noses, eyes, minds, and wallets its way.
Turning on the manipulation engine will not be one deliberate conscious act or one magnificent large piece of software. Lots of little changes will yield lots of little benefits. With billions of people, you can do a whole lot of A/B testing. Nobody will notice. Everybody’s feed is different and the fact that you see wording that is ever so slightly different will not trigger any of the societal mechanisms that will raise a reaction.
Jacob Riis used flash photography at the end of the 19th century to show the world how poor people lived in NYC, and he changed the world for the better. I cannot imagine how we can illuminate the modern plight of getting nudged into an ultimately unhappy existence that looms on the horizon.
LLMs have their limits, and where they excel makes a difference. As of June 2024, they continue to evolve. Anthrop\c Claude 3.5 works well for coding simple things with Python. It feels like the LLM has been heavily trained on existing code. Actually, it might be just as good in other applications as well. I wouldn’t know since I only use it for coding right now. Even on the paid plan, it has a message limit, which feels very 2023. So, I use the limited interaction where I get the highest benefit, which is coding. The artifact window is a great idea, and the speed of generation is appreciated. With gpt4o, I had to interleave work: make a request, switch to a different task while gpt4o sputtered out characters at Morse code speed. It probably runs on a colony of squids at the bottom of the Mariana Trench that OpenAI taught how to use Morse code with each arm.
And yes, an image like this I create with gpt4o. I don’t even know if Claude can do that. I don’t mind having multiple LLMs. I am gladly paying for both of them, as I do for search. Right now, I am very happy that there is more than one solution. I tried to use Google AI, but it was too complicated to figure out. To find the offering that fit mit my needs. And I am not aware of a key feature that I could only do with them. They already have all my email, read the entire Internet. If I can avoid it, I would not like to help them any further. Sure, if they were as good at coding as Claude, I would use them in a second. I have morals, but I cannot save the world single-handedly either.
One of the bigger fears I have is that LLMs might take the same turn that Google Search did. It was a great idea. It worked great, allowing for a phase of the Internet in the early 2000s that was very promising. Then it became what we suffer from today—a swamp. Barely functional. Generating around $150 profit for Google per user annually. Which means companies make more. Which means that I loose even more than that. The costs of using Google Search by being manipulated are much higher now than its benefits. The SEO world that Google Search presents is not a nice one. I happily give Kagi money to have some distance from that swamp.
Rüdiger Safranski schreibt über das Leben und damit ja auch Werk Goethes. Frank Arnold las “Schuld und Sühne” ganz hervorragend. Das gab den Ausschlag für dieses 28 Stunden Audiobuch. Mir gefiel es gut. Goethe lebte von 1749 bis 1832. Zeiten, in denen viel passierte. Auf Buchseiten und im echten Leben. In dem von Goethe und um ihn herum.
Der Autor bringt dieses sehr komplexe Geschehen sehr wohltuend in eine Form, die es aufnehmbar macht. Ich bin mir sicher, dass am Ende alles in Wirklichkeit noch viel verwobener war. Aber die Lesbarmachung dieser Zeit und dieses Lebens ist – in meiner Sicht – komplett gelungen.
Arnold van de Laar schreibt in “Schnitt!” über 28 Operationen der letzten Jahrhunderte und in einigen Fällen auch Jahrtausende. Das Buch ist nicht unbedingt etwas für schwache Nerven. Als Chirurg vergisst Van de Laar mitunter, dass nicht alle Menschen seine nüchterne und distanzierte Sichtweise in Bezug auf Körperversehrungen aller Art teilen können. Dem Inhalt tut das aber keinen Abbruch, wahrscheinlich sogar im Gegenteil.
Die Unterteilung in verschiedene Operationen, Operateure, Patienten, Zeiten und Regionen, die hier zusammen beleuchtet werden, tun dem Werk sehr gut. Van de Laar beleuchtet die Geschichte durch seine eigene, dabei zugleich immens einsichtsreiche Perspektive.
Seitdem es Zeitungen gibt, füllen sie sich zu 90 % mit schlechten Nachrichten. Ein Buch wie Schnitt! macht in klarstem Maße deutlich, dass wir durchaus schon weit gekommen sind. Wenn einem etwas fehlen sollte und man sich die Epoche der Behandlung aussuchen könnte, wäre die Auswahl immer sehr leicht: Heute. Ganz unbedingt heute. Vielleicht morgen. Aber auf keinen Fall in der Vergangenheit.
Was auch immer das Internet mit der Menschheit macht, es ist auch eine Plattform, auf der viele historische Kulturformen weiter existieren können.
Radio-Hörspiele zum Beispiel. Als der Massenkonsum schon längst zum Kino und dann zum Fernsehen umgezogen war, entwickelte das Radio seine vielleicht spannendsten Inhalte. Wie einige Podcaster gerade wieder neu entdecken, erlaubt eine Audioproduktion mit relativ einfachen Mitteln die Erzeugung von interessanten Szenarien.
Royal successions are based on who is related to whom in which way. Presumably in the biological way. Since most rules for successions are not based on maternal, like for instance the much more pragmatic jewish faith, it could be interesting to back up the pedigree with actual genetic evidence. Something that could have been done since decades. Given how easy it has become it is surprising that no tabloid has gone there yet to offer proof about certain differences between the official story and the actual relationships. I wonder if there efforts on the way to protect the genetic information of people in royal families.
There are stories that latest North Korean Kim makes efforts that the output of his body remains under his control. What a strange job: Honeyboy to the dictator.
It is probably possible to go back in time as well. There are probably a couple of relics that have traces of DNA. Once Corona is in the past we have allot of PCR capacity that is sitting around. I wonder how cheap these machines will become.